еҶҷеңЁжңҖеүҚ:
1.
http://www.swazzy.com/docs/hadoop/index.phpеҸҜд»Ҙиҫ“е…Ҙhadoopзұ», жҹҘзңӢе®ғзҡ„UMLе…ізі»еӣҫ.
2.
https://issues.apache.org/jira/browse/MAPREDUCE-279 Hadoop Map-Reduce 2.0(Yarn)зҡ„жһ¶жһ„ж–ҮжЎЈ,иҜҰз»ҶиҜҙжҳҺзӯү.
2013.07.14 LeaseManager--ж–Ү件еҶҷе…Ҙж—¶дёӯж–ӯ, еҗ„ж•°жҚ®иҠӮзӮ№йңҖиҰҒиҝӣиЎҢйӮЈдәӣж“ҚдҪң, жүҫеҲ°еҶҷе…Ҙж•°жҚ®жңҖе°‘зҡ„иҠӮзӮ№, жҸҗдәӨеҲ°NameNode, иҜҰз»ҶзңӢзұ»иҜҙжҳҺ.
2013.08.08 HDFS portion of ZK-based FailoverController еҹәдәҺzookeeperзҡ„иҮӘеҲҮжҚўNamenodeзҡ„activeдёҺstandyзҠ¶жҖҒ, https://issues.apache.org/jira/browse/HDFS-2185 жңүиҜҰз»Ҷзҡ„и®ҫи®Ўж–ҮжЎЈ.иҝҷйҮҢжңүдёҖзҜҮзҝ»иҜ‘ж–ҮжЎЈ,
http://blog.csdn.net/chenpingbupt/article/details/7922042, и§’иүІеғҸдёӢйқў:

дёӘдәәзҗҶи§Ј: ж•ҙдёӘжөҒзЁӢе°ұеғҸжҺ§еҲ¶еӨҡдёӘеқҰе…Ӣжү“д»—,ж”»еҮ»дёҖдёӘзӣ®ж ҮжңүдёҖиҫҶеқҰе…ӢеҸ‘зӮ®е°ұиЎҢ, еҰӮжһңжҺҘ收жҢҮд»Өзҡ„еқҰе…ӢжІЎеҸ‘зӮ®, йӮЈд№Ҳе°ұиҰҒз”ұе…¶е®ғеӨҮз”ЁеқҰе…ӢжқҘжү“,HealthMonitorе°ұеғҸжҳҜеқҰе…Ӣж“ҚдҪңе‘ҳ, иҙҹиҙЈжЈҖжҹҘеқҰе…ӢжҳҜдёҚжҳҜеҸҜд»Ҙжү“зӮ®, ActiveStandbyElectorе°ұеғҸж—¶еҲ»е°ҶеқҰе…ӢзҺ°зҠ¶еҸ‘йҖҒз»ҷжҢҮжҢҘзі»з»ҹ, жҺҘ收系з»ҹжҢҮд»Ө, жҠҠе®ғиҪ¬з»ҷжҢҮжҢҘе®ҳZKFailoverController(4.3зүҲжң¬дёәabstractзұ», е…·дҪ“е®һзҺ°DFSZKFailoverControllerдёҺMRZKFailoverController), з”ұжҢҮжҢҘе®ҳжқҘеҶіе®ҡжқҘеҸ‘зӮ®дёҺеҗҰеҸҠе°Ҷз»“жһңжҲ–зӯүеҫ…зҠ¶жҖҒз”ұActiveStandbyElectorеӣһйҰҲз»ҷжҢҮжҢҘзі»з»ҹ.
2013.08.09 INodeDirectoryдёӯchildrenдҪҝз”Ёnew ArrayList<INode>(5), еӣ дёәINodeе®һзҺ°Comparable<byte[]>жҺҘеҸЈ, compareTo(byte[] .)еҜ№жҜ”INodeзҡ„name(getBytes("UTF8")), еҗ‘dirдёӢеҠ е…ҘеўһеҠ ж–Ү件时, и°ғз”ЁINodeDirectory.addChild()ж–№жі•, еҲ©з”ЁCollectionsдёӯзҡ„static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) жҹҘжүҫиҰҒжҸ’е…Ҙзҡ„дёӢж Ү, binarySearchзҡ„еүҚжҸҗжҳҜlistе·Із»ҸsortиҝҮ.
жҺЁеҜј:nameеҗҚз§°дёҚе®ңй•ҝ, зӣ®еҪ•дёӢеҶ…е®№дёҚе®ңеӨҡ, жҹҘжүҫзү№е®ҡзӣ®еҪ•дёӢиҖ—ж—¶log(o).
з–‘й—®:INodeDirectory childдёәд»Җд№Ҳз”ЁListиҖҢдёҚз”ЁSetе‘ў?
2013.08.10
Understanding Hadoop Clusters and the Network:
http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/д»Һе°Ҷж–Ү件еҶҷе…ҘеҲ°hdfsејҖе§Ӣ, еҮҶеӨҮеҶҷж–Ү件(еӯҳж”ҫж•°жҚ®еә”иҜҘиҖғиҷ‘зҡ„жӢ“жү‘з»“жһ„(Rack Awareness), еҶҷж–Ү件иҝҮзЁӢдёӯ, еҶҷе®ҢеҗҺ, Job иҝҗиЎҢMap/Reduce, еӣ дёәж–°еўһжңҚеҠЎеҷЁиҮҙдҪҝзҡ„ж•°жҚ®дёҚеқҮиЎЎеҸҠеқҮиЎЎе·Ҙе…·.
Writing Files to HDFS,

,
Hadoop Rack Awareness,

,
Preparing HDFS Writes,

,
HDFS Write Pipeline,

,
HDFS Pipeline Write Success,

,
HDFS Multi-block Replication Pipeline,

,
NameNode Heartbeats,

,
Re-replicating Missing Replicas(жңүж•°жҚ®еӨҚжң¬дёўеӨұж—¶),

,
Client Read from HDFS,

,
Data Node reads from HDFS,

,
Map Task,
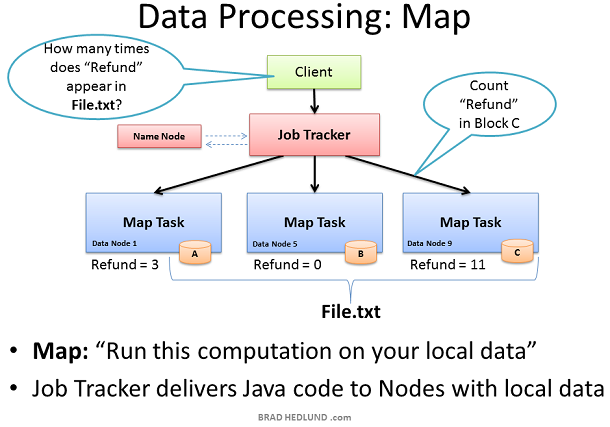
,
What if Map Task data isnвҖҷt local?

,
Reduce Task computes data received from Map Tasks,

,
Unbalanced Hadoop Cluster,

,
Hadoop Cluster Balancer,

,
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
HadoopеҸҠжәҗз Ғ HadoopеҸҠжәҗз Ғ HadoopеҸҠжәҗз Ғ HadoopеҸҠжәҗз Ғ
win 7 64дёҠзј–иҜ‘ Hadoop 2.7.3 жәҗз Ғ зҡ„зңҹе®һз»ҸеҺҶгҖӮ
hadoopжәҗз ҒпјҢе®ҳж–№пјҢж”ҫеҝғдёӢиҪҪпјҢе®Ңж•ҙзүҲпјҢйҳ…иҜ»hadoopжәҗд»Јз Ғзҡ„зӣ®зҡ„дёҚдёҖе®ҡйқһжҳҜе·ҘдҪңзҡ„йңҖиҰҒпјҢдҪ еҸҜд»ҘжҠҠд»–зңӢжҲҗдёҖз§Қдҝ®е…»пјҢйҖҡиҝҮйҳ…иҜ»hadoopжәҗд»Јз ҒпјҢеҠ ж·ұиҮӘе·ұеҜ№еҲҶеёғејҸзі»з»ҹзҡ„зҗҶи§ЈпјҢеҹ№е…»иҮӘе·ұиёҸе®һеҒҡдәӢзҡ„еҝғжҖҒгҖӮ
еҢ…еҗ«hadoop2.6.0жәҗз Ғе’ҢeclipseејҖеҸ‘hadoopжүҖз”ЁжҸ’件пјҢдёӢиҪҪеҚіеҸҜз”ЁгҖӮ
е®һжҲҳhadoopпјҢжәҗз ҒпјҢеҲҳй№ҸпјҢејҖеҗҜйҖҡеҗ‘дә‘и®Ўз®—зҡ„жҚ·еҫ„
hadoopжәҗз Ғ
ж–Ү件жҳҜhadoop 2.5.2жәҗз ҒпјҢд»Һе®ҳж–№зҪ‘з«ҷдёӢиҪҪзҡ„пјҢдҫӣеӣҪеҶ…и®ҝй—®дёҚжӯЈеёёзҡ„еҗҢеӯҰдёӢиҪҪ
hadoop 2.7.2 зҡ„еә•еұӮжәҗз ҒеҢ…гҖӮWelcome to Apacheв„ў HadoopВ®!
ж №жҚ®е®ҳзҪ‘mavenз»“жһ„жәҗз ҒиҮӘеҠЁз”ҹжҲҗzipжәҗз ҒеҢ…пјҢиҜ·ж”ҫеҝғдҪҝз”Ё
Hadoopжәҗз ҒеҲҶжһҗпјҲе®Ңж•ҙзүҲпјү,иҜҰз»ҶеҲҶжһҗдәҶHadoopжәҗз ҒзЁӢеәҸпјҢдёәеӯҰд№ Hadoopзҡ„дәәжҸҗдҫӣеҫҲеҘҪзҡ„е…Ҙй—ЁжҢҮеҜј
ITеҚҒе…«жҺҢ第дёүжңҹй…ҚеҘ—иҜҫе Ӯ笔记 Hadoopжһ¶жһ„еҲҶжһҗд№ӢйӣҶзҫӨз»“жһ„еҲҶжһҗ,Hadoopжһ¶жһ„еҲҶжһҗд№ӢHDFSжһ¶жһ„еҲҶжһҗ,Hadoopжһ¶жһ„еҲҶжһҗд№ӢNNе’ҢDNеҺҹз”ҹж–ҮжЎЈи§ЈиҜ»,Hadoop MapReduceеҺҹзҗҶд№ӢжөҒзЁӢеӣҫ.Hadoop MapReduceеҺҹзҗҶд№Ӣж ёеҝғзұ»Jobе’ҢResourceManager...
Hadoop rpcжәҗз ҒжҳҜд»ҺHadoopеҲҶзҰ»еҮәзҡ„ipc,еҺ»жҺүдәҶи®ӨиҜҒйғЁеҲҶ,йҷ„еҪ•дҪҝз”Ёж–ҮжЎЈ.дҪҝз”ЁеүҚиҜ·add libеҢ…commons-logging-*.*.*.jar(жҲ‘з”Ёзҡ„жҳҜ1.0.4)е’Ңlog4j-*.*.*.jar(жҲ‘зҡ„1.2.13) зӣёе…іblog post: ...
Ubuntu16.04+Eclipse neon.1+maven3.3.9жҲҗеҠҹеҜје…Ҙзҡ„Hadoop2.7.3е…ЁйғЁжәҗз Ғе·ҘзЁӢж–Ү件пјҢе·Іи§ЈеҶідәҶе…ЁйғЁзҡ„жҠҘй”ҷ
hadoop2.7.3зҡ„жәҗз ҒеҢ…пјҢhadoopе…іиҒ”жәҗз Ғзҡ„ж—¶еҖҷзӣҙжҺҘйҖүжӢ©е°ұеҸҜд»ҘжҹҘзңӢжәҗз ҒгҖӮжҳҜиҮӘе·ұйҖҡиҝҮmvnдёӢиҪҪзҡ„жәҗз Ғд№ӢеҗҺеҺӢзј©зҡ„гҖӮ
Hadoop2.7.1жәҗз Ғ(еҸҜзӣҙжҺҘеҜје…ҘEclipse)
еҹәдәҺHadoopеӣҫд№ҰжҺЁиҚҗзі»з»ҹжәҗз Ғ+ж•°жҚ®еә“.zipеҹәдәҺHadoopеӣҫд№ҰжҺЁиҚҗзі»з»ҹжәҗз Ғ+ж•°жҚ®еә“.zipеҹәдәҺHadoopеӣҫд№ҰжҺЁиҚҗзі»з»ҹжәҗз Ғ+ж•°жҚ®еә“.zipеҹәдәҺHadoopеӣҫд№ҰжҺЁиҚҗзі»з»ҹжәҗз Ғ+ж•°жҚ®еә“.zipеҹәдәҺHadoopеӣҫд№ҰжҺЁиҚҗзі»з»ҹжәҗз Ғ+ж•°жҚ®еә“.zipеҹәдәҺHadoopеӣҫд№Ұ...
hadoop 3.3.2жәҗз ҒеҢ…
йқһеёёиҜҰз»Ҷзҡ„linuxдёҠзҡ„hadoopйӣҶзҫӨжҗӯе»әж–ҮжЎЈпјҢеҸҜдҫӣеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶иғҪеӨҹд»ҺдёӯиҺ·зӣҠ
hadoopйӣҶзҫӨе®ү装笔记пјҢжҲ‘дёӘдәәеңЁиҮӘе·ұзҡ„жң¬жңәиҷҡжӢҹ3еҸ°жңәеҷЁпјҢжҗӯе»әhadoopзҡ„еӯҰд№ зҺҜеўғпјҢеңЁе®үиЈ…иҝҮзЁӢдёӯпјҢеҮәзҺ°иҝҷж ·йӮЈж ·зҡ„й—®йўҳпјҢ并记еҪ•дёӢжқҘеҲҶдә«з»ҷеӨ§е®¶пјҢеёҢжңӣйғҪж–°жүӢжңүеё®еҠ©гҖӮ